In the previous blog we looked at how we could transfer a few bytes between processor cores thanks to the flat memory space. However, there are applications where we will want transfer large blocks of data between the cores, to do so it is more efficient to use the Direct Memory Access (DMA) than to let the CPU perform the transfer.
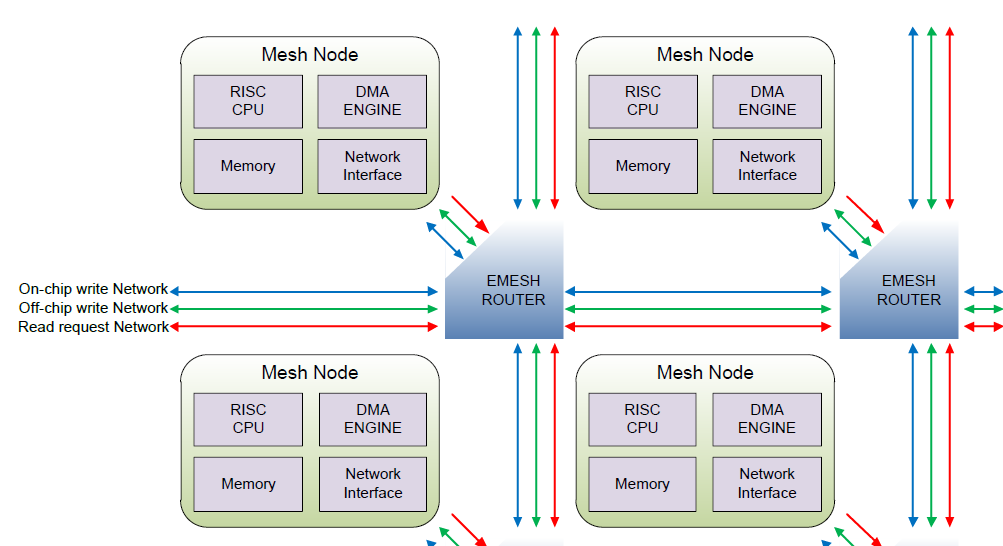
Each of the cores with the epiphany has a multi-channel DMA engine, at its most basic level, DMA transfers data into or out of memories without CPU intervention once the CPU has set up the transfer. This means that using DMA can significantly increase system performance as it frees up the processor core which is very important for both system and embedded developers.
Support for DMA within the Epiphany chip is provided by the Epiphany Hardware Utility library also called the elib which we have been using previously for functions like the e_read() and e_write(). The functions provided are detailed within the Epiphany SDK reference, for reference I am using 5.13.09.10 for this series.
To demonstrate how we can work with the DMA engine in the Epiphany I have created a simple example which uses a two core workgroup. The first core in the work group generates a number of bytes of data within its own address space, while the second core attains its core ID and writes it into its memory space. The first core then uses DMA to transfer its calculated bytes to a second cores memory. To do this we use the e_dma_copy() command which uses DMA channel one to transfer the number of bytes we wish from the source to the destination.
This frees upthe first core to continue its processing which improves the system performance, to demonstrate this is working we then use the host to read out and display the number of bytes transferred from the second cores memory along with the core ID which the processor has placed there to show it location.
While this is a very simple demo it enables us to understand how we can transfer data between cores. We will be using DMA more when we look at how we can implement more exciting applications like cryptography, image and signal processing.
Within the elib there is support to allow creation of more advanced DMA architectures by the creation of buffer descriptors which define the channel to be used, source and destination and the also the ability to connect descriptors together to form chains to more efficiently transfer data. The elib also contains a number of functions to start, test if the channel is busy and wait for channel to become free.
One aspect which I think is worth expanding a little on finally here is that of the stride, in this example we have a unity stride as the addresses increments by one byte for an 8 bit transfer and 4 bytes for a 32 bit transfer and so on. However in some applications we do not wish this to be the case we may wish to transfer from the source to destination memory and have a separation between addresses in either direction this is achieved by changing the stride.
We can use the stride to help create 2D DMA architectures which is very interesting when it comes to video processing applications as we tend to work in 2 dimensional arrays when using video.
You can access the code for this example here
Previous Blogs in this series are available below
Part 5 Epiphany Memory Map
Part 4 Work Groups
Part 3 Hello World
Part 2 The SDK
Part 1 Introduction
