Having cycled through each of the processors within the 16 core epiphany and run the hello world programme the next stage is to utilise the parallel processing capabilities and run the hello world programme at the same time on multiple processors. This is very simple to do and allows me to introduce a few simple concepts which we will be using very often.
The epiphany is a very flexible device in that we can segment the device into a number of regions which are capable of executing different programmes. These segments can be as small as a single core or as large as all of the cores in the device, these segments are called workgroups within the epiphany nomenclature.
For this example we will be segmenting the core up into the number of smaller work groups to demonstrate not only the parallel processing but also work group control, in this case we will use 8 work groups of two processors each. The application will move the two element work group through all of the 16 cores within the device.
The devices within the core are arranged as into four rows and four columns as shown in the diagram below
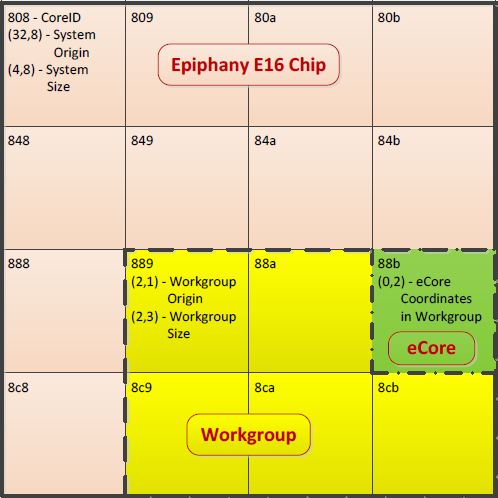
As we will be communicating with multiple cores this example will also store the output string from each core within the cores own 32 KB address space.
To create this demonstration we will need three files
• Host application which sets up and manages the workgroups and retrieves the information from each of the cores in the workgroup
• Core application 1 this runs on the first core in the work group and prints hello world from core 1 along with the core ID
• Core application 2 this runs on the second core in the work group and prints hello world from core 2 along with the core ID.
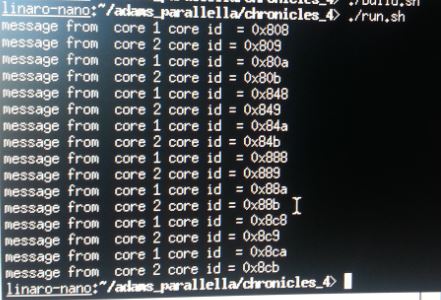
When the host application has completed running you will see all of the cores have been output in groups of two which will give us the following end result
Within the Host application we need to do the following
• Initialize, reset and get the platform information as we did previously for the single core hello world. Using e_init(), e_reset_system & e_get_platform_info
• The next step is then to create work group which is 1 row by two columns wide i.e. two processors next to each other on the same row. This is achieved using the e_open command to define the work group origin and the size of the work group in rows and columns
• Reset the newly created work group
• Load the two applications into the different cores within the work group, using the e_load function to ensure the applications run in parallel once loaded the cores are not started. If we were using the same application then we could use the e_load_group command.
• With both cores loaded with their respective applications we can then run the applications using the e_start_group function.
• Each application stores its messages at predetermined memory locations, e_read is thus used access the memory location on both cores within the work group and to access the resultant messages.
The target application is again much simpler than the host application and simply uses pointers to its memory location to store messages to be passed to the host. Again all the code is available under the Parallella chronicles git hub repository.
https://github.com/ATaylorCEngFIET/Parallella-Chronicles
Previous Instalments
https://parallella.org/2015/01/14/parallella-chronicles-part-three/

Thanks for writing these tutorials – as a beginner MIMD programmer, these step-by-step “chronicles” are great to convert from traditional C++/threads based thinking to doing useful stuff with a Parallella.
I hope you’re planning to write more – it feels like we’re almost at the best part…
Cheers, -Harry
PS: If you’re looking for ideas for topics, a +1 for doing an operation on memory larger than the Ephiphany has internally: perhaps taking a large float array (10 seconds of audio @44.1kHz?) and multiplying it by a scalar?
Hi Adam,
Thank you for this very usefull hands-on.
Just a question : in chronicle 3, what is the meaning of the offset in e_alloc, and why choosing 0x01000000 than other values ( I tried with 0X00000000 and 0x00100000- retuned or dumb values).
I read the documentation on e_alloc and try to match memory map document, but it doesn’t help (me).
Kind regards,
Albert
Hi Adam,
I found the answer here : https://parallella.org/forums/viewtopic.php?f=13&t=1869&p=11478&hilit=offset&sid=1620cae47a2d32182d7fd542362331b3#p11478
Kind regards,
Albert
[…] Part 4 Work Groups […]
[…] Part 4 Work Groups […]