Introduction
In this blog post we will describe how we wrote an image processing demo for the Parallella prototype which we’ve been experimenting with and detail some of the problems we faced along the way and how we overcame them.
We chose to use OpenCL rather than straight C since we thought it would be simpler to develop data parallel oriented code in this manner. More on this later…
The Problem
We had four cameras, each hooked up to a Raspberry Pi which were all connected to a Parallella by way of a network switch. The following figure outlines the setup:
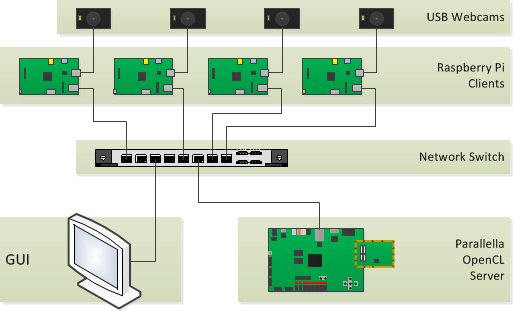
The problem we decided to solve and demonstrate was to capture images from the cameras and process them using OpenCL on the Parallella board. Image processing, by its nature, lends itself well to parallel processing. Many image processing algorithms are concerned with applying a function over each individual pixel or block of pixels in the image simultaneously.
We wanted to show that we could use the Epiphany architecture to accomplish several of these processing tasks. The first algorithm chosen was Sobel edge detection, to ensure that we could familiarise ourselves with the toolchain and kept the problem simple enough that we could achieve results in real time if necessary.
Initially we wanted to do a Circular Hough transform which is where circles are detected in a binary image, but lacking atomic operations in the current alpha version of the OpenCL implementation within the SDK made it impossible to do it in the short amount of time we had available.
The Camera Code
Each Raspberry Pi was provisioned with an Erlang node which was responsible for capturing image frames via the OpenCV library. OpenCV was only used to grab frames from the webcams and perform the grayscale conversion but no further processing was done on the Pi after that. In order to accomplish this, we wrote a simple Erlang NIF (native implemented functions) library which allowed us to capture frames, the exposed API is:
any_device/0
new_frame/1, query_frame/2
frame_to_tuple/1
loop_send_frames/0
As you can see the API is pretty simple, all we wanted to do was to capture an image frame, convert it to grayscale and pass it on to the Parallela for further processing. We used Erlang/OTP’s standard components, such as gen_server, supervisors to create our application and we used gen_tcp as the transport mechanism in order to send the frames across since we had previous code to do this and it turns out to be efficient.
The OpenCL Code
The Parallella was provisioned with an Erlang node which acquired image frames from a Raspberry Pi and processed the data using a custom OpenCL NIF. You may be wondering at this point why we didn’t make use of Tony Rogvall’s excellent OpenCL bindings.This was due to the fact that we are using a prototype platform and a prototype SDK and as such, we did run into some trouble getting it to run on the Parallella without segfaults and did not have the time to change the codebase to support everything we needed.
The OpenCL NIF we wrote has the following API:
initialize/0
terminate/0
transform/1
Where initialize is responsible for ensuring that OpenCL is setup and a context is acquired, terminate cleans up all of the OpenCL variables which need to be freed, and transform executes an OpenCL transform on the input data. transform works by loading the data into device memory (Parallela being the device here), processes it and writes the result back to a binary which is then returned to Erlang.
Conclusion
The results of our experiment and the code we have developed on our Parallella board can be found at this GitHub repository, released under the Apache 2 open source license.
After spending some time with the platform, we realised that OpenCL does not map to the Parallella in the same manner as it does for a GPU due to the nature of the architecture. This can be seen as a benefit since the Parallella platform allows for more freedom where scheduling the computation of different expressions is concerned. In OpenCL one is forced to use the scheduling that the hardware specifies.
Quoting David Richie of Brown Deer Technology, the lead developer of OpenCL for the Epiphany architecture:
“Something to keep in mind. OpenCL was designed for GPUs with all other processors being an afterthought. The idea of very large workgroup sizes is driven by their being a multi-threaded architecture. A GPU must have “thousands” of threads in flight (concurrently executed) to be efficient. Epiphany and (multicore CPUs) have no (small) multi-threading support, so the aim for effiicent coding is completely different. The best way to use Epiphany is to map workgroup size to the number of physical cores. There is no advantage to going beyond this since you consume stack and add overhead for context switching. That is basically why we settled on the model we have now, known as “pth”.”
Ed Tate, who did the heavy lifting on this experiment, presented his experience working with this application and some plans for his future explorations at the “Preparing for Parallella” event held at Bletchley Park in July. The slides Ed presented are available here.
We’ve been investigating using various other parallel architectures for some time now and it is our intention to attempt to map parallel algorithms to them in order to assess their viability within commercial server based solutions.
In the next blog post we will discuss intensionality and how it can help us both express parallel algorithms in a concise manner, but also obtain a coherent semantic model for doing distributed computations across many-core machines. We will also delve into the details of the technology we are building within Erlang in order to obtain good performance and demonstrate how it could possibly map to the Parallella architecture.
This has been an interesting experiment for us as we explored the Parallella platform using a simple application as a case study. We are looking forward to diving deeper into the Parallella and publishing our findings here via further blog posts.
