We at Erlang Solutions have had the pleasure of coming into contact with shiny Parallella board prototype and over the past few weeks we have been exploring how to utilise it as part of our experiments in the multicore domain.
In this blog post Edward Tate, our resident OpenCL hacker, introduces the reasons we have been interested in making use of the Parallela: Data Parallelism and OpenCL.
What is data parallelism?
Data parallelism is where multiple distinct units of data are operated upon simultaneously by the same task. On the CPU this would mean distributing the data across cores and executing an operation such as multiplication upon distinct units of memory at the same time. Given that CPUs nowadays contain 8 or more cores and data parallel problems may need to operate upon data which extends much past this boundary (an image for example may contain 1024*1024 pixels), it is necessary to devise mechanisms which can partition the data appropriately so that the cores can be efficiently utilised.
If we were to use Erlang processes to partition the data, we would be using Erlang’s runtime directly, and thus the ‘overhead’ of our problem relative to straight C code would be the garbage collector and the scheduler; the GC due to the space necessary to allocate processes which contain distributed data within a task, and the scheduler due to it being the mapping of processes to multiple cores.
We could envisage writing a piece of C or C++ code which efficiently caters for these types of problems without any scheduling or GC overhead. In fact this is what was developed as part of the ParaPhrase project (FastFlow)[1].
However, devices which already perform partitioning in hardware (such as a GPU) are well suited to solving these types of problems since a scheduling mechanism in software is no longer necessary. This is by and large what the Erlang world has resorted to when dealing with image processing and audio processing tasks in the past.
The Epiphany architecture does not have this type of partitioning of data across threads in hardware which raises the question of scheduling efficiently across cores in software; this is an area of research that we are interested in investigating since Erlang’s scheduler was not specifically designed with parallelism in mind from the get go.
Why Erlang?
Parallel data structures and algorithms are becoming much more important with the advent of multicore chips. Being aware of algorithms which have been parallelized and methods for operating upon data in parallel have become central to understanding how to effectively compute problems within these constraints.
Erlang is a functional programming language which was designed with concurrency oriented programming in mind, meaning problems which require the explicit programming of processes and their communication, or the utilisation of patterns (or behaviours) which provide generic means of representing the problem.
We wanted to extend Erlang’s applicability to the domains of video processing, audio processing and image processing, which inherently contain problems with massive amounts of data parallelism, so naturally we looked to GPUs and other hardware devices such as the Epiphany devices.
Intensional Parallelism
In addition to wanting to attain efficiency where data parallel algorithms are concerned, we have been investigating different ways of expressing parallel programs such that they are comprehensible and to provide a methodology which allows for the debugging of such programs without too many headaches.
One example of an alternate approach is the GLU Lucid language developed at SRI’s Computer Science Laboratory which allows for expressing parallel algorithms in a simple form, where Lucid acts as a coordination language and underlying sequential C code is responsible for operating upon the data in parallel.
If you wish to find out more about parallelism in Lucid please see [2], [3] and [4].
The Parallella has been of great interest to us from its inception, since we have been developing such a coordination DSL in-house for quite some time that we envisage mapping to the Epiphany architecture in the future.
OpenCL
Another idea which we explored was to make use of OpenCL within Erlang. We made use of the great OpenCL binding available at [5] for quite some time as part of the ParaPhrase project. There we developed an application framework which allows for the execution of arbitrary OpenCL kernels within a node. As an extension to this project we wanted to see how the Parallella would fare against a GPU in terms of performance and more importantly power consumption since power consumption in data centres is becoming a major issue.
More information about OpenCL on Parallella can be found at this blog post.
On the Parallella so far, we have managed to create our own OpenCL binding (with some help from David Richie from Brown Deer Technology) in the form of an Erlang NIF module. A NIF is a function that is implemented in C instead of Erlang which behaves more or less like an Erlang function. More information about NIFs can be found at [6]. We are using this in an upcoming demo for the Erlang User Conference in Stockholm next month.
The application area we have chosen is vision systems (object tracking) and here’s a sneak peek at the overall architecture of our system:
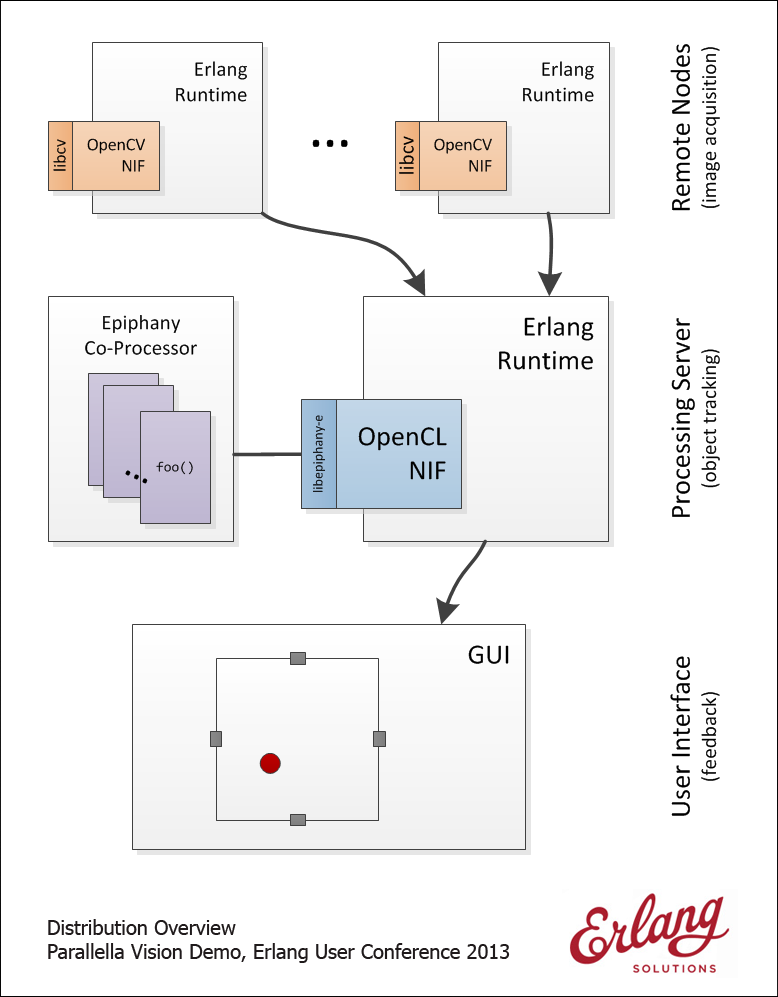
(click thumbnail for a much larger version)
Future plans
In the next blog post, we will talk about the implementation details and the challenges we have tackled during the development of this vision demo. We might even have a short video of it in operation!
Stay tuned for more details and feel free to get in touch if you have any queries or comments.
References
[1] http://sourceforge.net/projects/mc-fastflow/[2] http://soft.vub.ac.be/soft/edu/mscprojects/2010_2011/lucid-on-tilera
[3] http://www.csl.sri.com/papers/sri-csl-94-06/sri-csl-94-06.pdf
[4] http://books.google.co.uk/books/about/Multidimensional_Programming.html?id=4f3WZaLgL9gC
[5] http://www.erlang.org/doc/man/erl_nif.html
[6] http://github.com/tonyrog/cl
