 A newly developed compiler [0] and paper describing the parallel language [1] are released today which enable a novel approach to parallel and distributed programming for the many-core Epiphany coprocessor included in Parallella as well as multi-core CPUs and distributed clusters. The LOLCODE language, originally developed in 2007, has been extended to include parallel and distributed programming concepts directly within the language specification. The work will be presented at the 7th NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar-17) [2] held in conjunction with the 31st IEEE International Parallel & Distributed Processing Symposium (IPDPS ’17) [3].
A newly developed compiler [0] and paper describing the parallel language [1] are released today which enable a novel approach to parallel and distributed programming for the many-core Epiphany coprocessor included in Parallella as well as multi-core CPUs and distributed clusters. The LOLCODE language, originally developed in 2007, has been extended to include parallel and distributed programming concepts directly within the language specification. The work will be presented at the 7th NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar-17) [2] held in conjunction with the 31st IEEE International Parallel & Distributed Processing Symposium (IPDPS ’17) [3].
The compiler builds on prior work developing an OpenSHMEM implementation for Epiphany (paper: [4], code: [5]) and advances in the run-time and interoperability for Epiphany (paper: [6], resources: [7]), however these are only required if running on the Epiphany coprocessor. Strictly speaking, the LOLCODE compiler presented here is a source-to-source compiler, allowing high performance compiled code to be executed in parallel on any platform with an OpenSHMEM implementation. It was developed on Parallella, then tested on a multi-core x86 workstation with the open source reference implementation for OpenSHMEM [8], as well as a Cray XC40 supercomputer [9] used for High Performance Computing (HPC).
The language with parallel extensions is designed to teach the concepts of Single Program Multiple Data (SPMD) execution and Partitioned Global Address Space (PGAS) memory models used in Parallel and Distributed Computing (PDC), but in a manner that is more appealing to undergraduate students or even younger children.
A preprint of the scholarly paper is available on arXiv [1] and has received some very positive academic peer reviews:
| “The authors have developed a compiler and demonstrated parallel applications on a $99 Parallella board. This goes a ways toward establishing its usefulness for teaching PDC with reasonable resources. The paper is clear and well organized. Code examples serve well to show what the parallel extensions are and how they work.” — Reviewer #3 | “The paper is [sic] relevent. (Personally, I have reservations about this approach given that it may encourage slang that is already made its way into student’s deplorable writing.) The work has value and has novel elements in its approach. The paper describes a novel and coherent (as far a program structure and methodology) approach to making HPC/PDC available and teachable to students.” — Reviewer #4 |
The new language specification, LOLCODE 2.0 [10], corrects many of the language deficiencies that held back the language from use in high performance software development including:
- Dynamic typing removed in favor of statically typed variables
- Transition to a compiled language from an interpreted language
- Addition of real arrays that may be dynamically sized at run-time
- Improved support for loops
- PGAS concepts for distributed memory
- Remote memory access
- Parallel synchronization with barriers and locks
The LOLCODE 2.0 compiler [0] and paper [1] describe additional details about the language extensions and include example codes such as a parallel gravitational n-body calculation and a parallel NVE molecular dynamics simulation using a Lennard-Jones potential and a velocity-verlet integrator. A simple LOLCODE 2.0 example parallel application is described below.
Example Application: Computing Pi
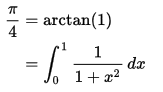 The example presented below performs a parallel Pi calculation across multiple processing elements written in LOLCODE with parallel extensions. Each parallel processing element computes a piece of the total sum using the Leibniz formula for Pi [11]. A final summation across all parallel processing elements is performed, demonstrating the concept of remote memory access and linear parallel reductions. A global barrier must occur (HUGZ) to guarantee that each processing element has completed calculating their partial sum (VAR). Each processing element accumulates the partial sum from every processing element (ME and MAH FRENZ). In this code, the precision of the calculated result improves as the total number of processing elements increases to machine precision. Alternatively, you can increase the number of integral steps, N.
The example presented below performs a parallel Pi calculation across multiple processing elements written in LOLCODE with parallel extensions. Each parallel processing element computes a piece of the total sum using the Leibniz formula for Pi [11]. A final summation across all parallel processing elements is performed, demonstrating the concept of remote memory access and linear parallel reductions. A global barrier must occur (HUGZ) to guarantee that each processing element has completed calculating their partial sum (VAR). Each processing element accumulates the partial sum from every processing element (ME and MAH FRENZ). In this code, the precision of the calculated result improves as the total number of processing elements increases to machine precision. Alternatively, you can increase the number of integral steps, N.
pie.lol:
HAI 2.0
I HAS A N ITZ SRSLY A NUMBR AN ITZ 10
I HAS A H ITZ SRSLY A NUMBAR AN ITZ QUOSHUNT OF 1.0 AN PRODUKT OF N AN MAH FRENZ
I HAS A S ITZ SRSLY A NUMBR AN ITZ PRODUKT OF N AN ME
WE HAS A VAR ITZ SRSLY A NUMBAR AN IM SHARIN IT
IM IN YR LOOP UPPIN YR K TIL BOTH SAEM K AN N
I HAS A X ITZ SRSLY A NUMBAR AN ITZ QUOSHUNT OF 4.0 ...
AN SUM OF 1.0 AN SQUAR OF PRODUKT OF H AN ...
SUM OF 0.5 AN SUM OF S AN K
VAR R SUM OF VAR AN X
IM OUTTA YR LOOP
VAR R PRODUKT OF VAR AN H
HUGZ
I HAS A PIE ITZ SRSLY A NUMBAR
IM IN YR LOOP UPPIN YR K TIL BOTH SAEM K AN MAH FRENZ
TXT MAH BFF K, PIE R SUM OF PIE AN UR VAR
IM OUTTA YR LOOP
BOTH SAEM 0 AN ME, O RLY?
YA RLY,
VISIBLE "PIE IZ: " PIE
OIC
KTHXBYE
The code may be compiled with LOLCODE compiler, which creates the serial executable a.out:
lcc pie.lol
And the resulting binary may executed in parallel using 16 processing elements (unique to Parallella, other platforms vary):
coprsh -np 16 ./a.out
Resulting in the output:
PIE IZ: 3.141594
See the LOLCODE compiler source code repository [0] for more information and example codes.
References
[0] LOLCODE compiler, https://github.com/browndeer/lcc
[1] Richie D., Ross J. (2017) I CAN HAS SUPERCOMPUTER? A Novel Approach to Teaching Parallel and Distributed Computing Concepts Using a Meme-Based Programming Language, https://arxiv.org/abs/1703.10242
[2] 7th NSF/TCPP Workshop on Parallel and Distributed Computing Education (EduPar-17), https://grid.cs.gsu.edu/~tcpp/curriculum/?q=edupar17
[3] IPDPS – IEEE International Parallel and Distributed Processing Symposium, http://www.ipdps.org/
[4] Ross J., Richie D. (2016) An OpenSHMEM Implementation for the Adapteva Epiphany Coprocessor. In: Gorentla Venkata M., Imam N., Pophale S., Mintz T. (eds) OpenSHMEM and Related Technologies. Enhancing OpenSHMEM for Hybrid Environments. OpenSHMEM 2016. Lecture Notes in Computer Science, vol 10007. Springer, Cham (online)
[5] ARL OpenSHMEM for Epiphany, https://github.com/USArmyResearchLab/openshmem-epiphany
[6] David A. Richie, James A. Ross, Advances in Run-time Performance and Interoperability for the Adapteva Epiphany Coprocessor, Procedia Computer Science, Volume 80, 2016, Pages 1531-1541, ISSN 1877-0509, http://dx.doi.org/10.1016/j.procs.2016.05.478. (online)
[7] Brown Deer Technology COPRTHR-2 Epiphany/Parallella Developer Resources, http://www.browndeertechnology.com/resources_epiphany_developer_coprthr2.htm
[8] OpenSHMEM Reference Implementation, https://github.com/openshmem-org/openshmem
[9] U.S. Army Research Laboratory DoD Supercomputing Resource Center: Excalibur Quick Start Guide, https://www.arl.hpc.mil/docs/excaliburUserGuide.html
[10] LOLCODE 2.0 specification, https://github.com/browndeer/lolcode-spec
[11] Leibniz formula for π (Wikipedia)
