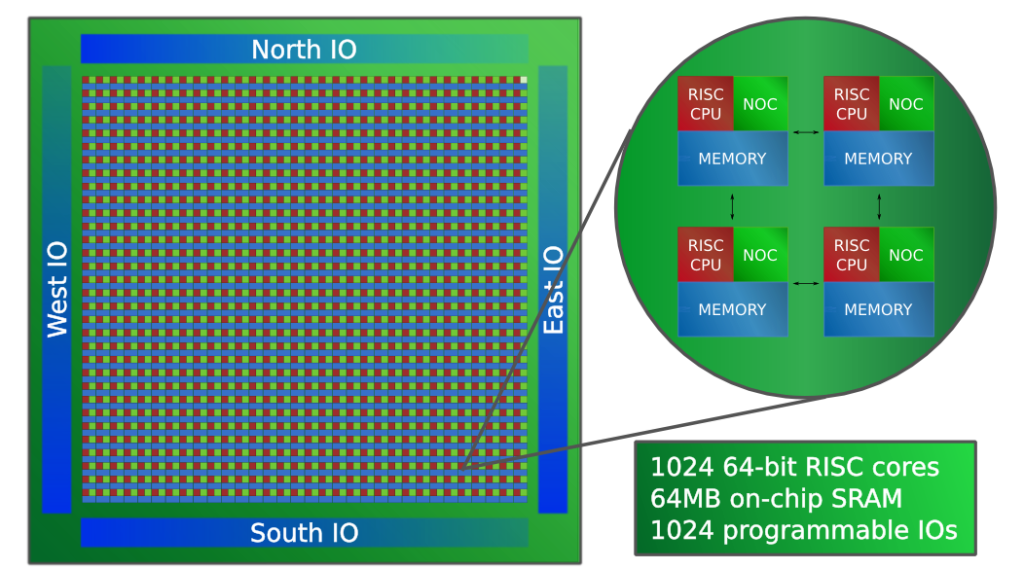
I am happy to report that we have successfully taped out a 1024-core Epiphany-V RISC processor chip at 16nm. The chip has 4.5 Billion transistors, which is 36% more transistors than Apple’s latest 4 core A10 processor at roughly the same die size. Compared to leading HPC processors, the chip demonstrates an 80x advantage in processor density and a 3.6x advantage in memory density.
Epiphany-V Summary:
- 1024 64-bit RISC processors
- 64-bit memory architecture
- 64-bit and 32-bit IEEE floating point support
- 64 MB of distributed on-chip SRAM
- 1024 programmable I/O signals
- Three 136-bit wide 2D mesh NOCs
- 2052 separate power domains
- Support for up to One Billion shared memory processors
- Support for up to One Petabyte of shared memory
- Binary compatibility with Epiphany III/IV chips
- Custom ISA extensions for deep learning, communication, and cryptography
- TSMC 16FF process
- 4.56 Billion transistors, 117mm^2 silicon area
- DARPA funded
Chips will come back from TSMC in 4-5 months. We will not disclose final power and frequency numbers until silicon returns, but based on simulations we can confirm that they should be in line with the 64-core Epiphany-IV chip adjusted for process shrink, core count, and feature changes. For more information, see report below:
Cheers,
Andreas
This research was developed with funding from the Defense Advanced Research Projects Agency (DARPA). The views, opinions and/or findings expressed are those of the author and should not be interpreted as representing the official views or policies of the Department of Defense or the U.S. Government.
